ARMv8 内存系统学习笔记
目录:
References
- https://developer.arm.com/documentation/100941/0100
- https://developer.arm.com/documentation/den0024/a/Caches
- https://developer.arm.com/documentation/den0024/a/Memory-Ordering
- https://developer.arm.com/documentation/dui0489/c/arm-and-thumb-instructions/miscellaneous-instructions/dmb--dsb--and-isb
- https://en.cppreference.com/w/cpp/atomic/memory_order
Cache coherency
Cacheability
Normal memory 可以设置为 cacheable 或 non-cacheable,可以按 inner 和 outer 分别设置。
Shareability
设置为 non-shareable 则该段内存只给一个特定的核使用,设置为 inner shareable 或 outer shareable 则可以被其它观测者访问(其它核、GPU、DMA 设备),inner 和 outer 的区别是要求 cache coherence 的范围,inner 观测者和 outer 观测者的划分是 implementation defined。
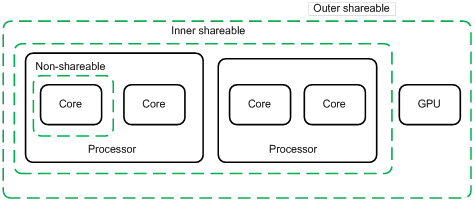
PoC & PoU
当 clean 或 invalidate cache 的时候,可以操作到特定的 cache 级别,具体地,可以到下面两个“点”:
Point of coherency(PoC):保证所有能访问内存的观测者(CPU 核、DSP、DMA 设备)能看到一个内存地址的同一份拷贝的“点”,一般是主存。

Point of unification(PoU):保证一个核的 icache、dcache、MMU(TLB)看到一个内存地址的同一份拷贝的“点”,例如 unified L2 cache 是下图中的核的 PoU,如果没有 L2 cache,则是主存。

当说“invalidate icache to PoU”的时候,是指 invalidate icache,使下次访问时从 L2 cache(PoU)读取。
PoU 的一个应用场景是:运行的时候修改自身代码之后,使用两步来刷新 cache,首先,clean dcache 到 PoU,然后 invalidate icache 到 PoU。
Memory consistency
ARMv8-A 采用弱内存模型,对 normal memory 的读写可能乱序执行,页表里可以配置为 non-reordering(可用于 device memory)。
Normal memory:RAM、Flash、ROM in physical memory,这些内存允许以弱内存序的方式访问,以提高性能。
单核单线程上连续的有依赖的 str 和 ldr 不会受到弱内存序的影响,比如:
str x0, [x2]
ldr x1, [x2]
Barriers
ISB
刷新当前 PE 的 pipeline,使该指令之后的指令需要重新从 cache 或内存读取,并且该指令之后的指令保证可以看到该指令之前的 context changing operation,具体地,包括修改 ASID、TLB 维护指令、修改任何系统寄存器。
DMB
保证所指定的 shareability domain 内的其它观测者在观测到 dmb 之后的数据访问之前观测到 dmb 之前的数据访问:
str x0, [x1]
dmb
str x2, [x3] // 如果观测者看到了这行 str,则一定也可以看到第 1 行 str
同时,dmb 还保证其后的所有数据访问指令能看到它之前的 dcache 或 unified cache 维护操作:
dc csw, x5
ldr x0, [x1] // 可能看不到 dcache clean
dmb ish
ldr x2, [x3] // 一定能看到 dcache clean
DSB
保证和 dmb 一样的内存序,但除了访存操作,还保证其它任何后续指令都能看到前面的数据访问的结果。
等待当前 PE 发起的所有 cache、TLB、分支预测维护操作对指定的 shareability domain 可见。
可用于在 sev 指令之前保证数据同步。
一个例子:
str x0, [x1] // update a translation table entry
dsb ishst // ensure write has completed
tlbi vae1is, x2 // invalidate the TLB entry for the entry that changes
dsb ish // ensure that TLB invalidation is complete
isb // synchronize context on this processor
DMB & DSB options
dmb 和 dsb 可以通过 option 指定 barrier 约束的访存操作类型和 shareability domain:
| option | ordered accesses (before - after) | shareability domain |
|---|---|---|
oshld |
load - load, load - store | outer shareable |
oshst |
store - store | outer shareable |
osh |
any - any | outer shareable |
ishld |
load - load, load - store | inner shareable |
ishst |
store - store | inner shareable |
ish |
any - any | inner shareable |
nshld |
load - load, load - store | non-shareable |
nshst |
store - store | non-shareable |
nsh |
any - any | non-shareable |
ld |
load - load, load - store | full system |
st |
store - store | full system |
sy |
any - any | full system |
One-way barriers
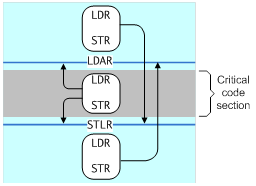
- Load-Acquire (LDAR): All loads and stores that are after an LDAR in program order, and that match the shareability domain of the target address, must be observed after the LDAR.
- Store-Release (STLR): All loads and stores preceding an STLR that match the shareability domain of the target address must be observed before the STLR.
- LDAXR
- STLXR
Unlike the data barrier instructions, which take a qualifier to control which shareability domains see the effect of the barrier, the LDAR and STLR instructions use the attribute of the address accessed.
C++ & Rust memory order
Relaxed
Relaxed 原子操作只保证原子性,不保证同步语义。
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
上面代码在 ARM 上编译后使用 str 和 ldr 指令,可能被乱序执行,有可能最终产生 r1 == r2 == 42 的结果,即 A 看到了 D,C 看到了 B。
典型的 relaxed ordering 的使用场景是简单地增加一个计数器,例如 std::shared_ptr 中的引用计数,只需要保证原子性,没有 memory order 的要求。
Release-acquire
Rel-acq 原子操作除了保证原子性,还保证使用 release 的 store 和使用 acquire 的 load 之间的同步,acquire 时必可以看到 release 之前的指令,release 时必看不到 acquire 之后的指令。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string *> ptr;
int data;
void producer() {
std::string *p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer() {
std::string *p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fires
assert(data == 42); // never fires
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
上面代码中,一旦 consumer 成功 load 到了 ptr 中的非空 string 指针,则它必可以看到 data = 42 这个写操作。
这段代码在 ARM 上会编译成使用 stlr 和 ldar,但其实 C++ 所定义的语义比 stlr 和 ldar 实际提供的要弱,C++ 只保证使用了 release 和 acquire 的两个线程间的同步。
典型的 rel-acq ordering 的使用场景是 mutex 或 spinlock,当释放锁的时候,释放之前的临界区的内存访问必须都保证对同时获取锁的观测者可见。
Release-consume
和 rel-acq 相似,但不保证 consume 之后的访存不会在 release 之前完成,只保证 consume 之后对 consume load 操作有依赖的指令不会被提前,也就是说 consume 之后不是临界区,而只是使用 release 之前访存的结果。
Note that currently (2/2015) no known production compilers track dependency chains: consume operations are lifted to acquire operations.
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string *> ptr;
int data;
void producer() {
std::string *p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer() {
std::string *p2;
while (!(p2 = ptr.load(std::memory_order_consume)))
;
assert(*p2 == "Hello"); // never fires: *p2 carries dependency from ptr
assert(data == 42); // may or may not fire: data does not carry dependency from ptr
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
上面代码中,由于 assert(data == 42) 不依赖 consume load 指令,因此有可能在 load 到非空指针之前执行,这时候不保证能看到 release store,也就不保证能看到 data = 42。
Sequentially-consistent
Seq-cst ordering 和 rel-acq 保证相似的内存序,一个线程的 seq-cst load 如果看到了另一个线程的 seq-cst store,则必可以看到 store 之前的指令,并且 load 之后的指令不会被 store 之前的指令看到,同时,seq-cst 还保证每个线程看到的所有 seq-cst 指令有一个一致的 total order。
典型的使用场景是多个 producer 多个 consumer 的情况,保证多个 consumer 能看到 producer 操作的一致 total order。
#include <thread>
#include <atomic>
#include <cassert>
std::atomic<bool> x = {false};
std::atomic<bool> y = {false};
std::atomic<int> z = {0};
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst))
;
if (y.load(std::memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst))
;
if (x.load(std::memory_order_seq_cst)) {
++z;
}
}
int main() {
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join(); b.join(); c.join(); d.join();
assert(z.load() != 0); // will never happen
}
上面的代码中,read_x_then_y 和 read_y_then_x 不可能看到相反的 x 和 y 的赋值顺序,所以必至少有一个执行到 ++z。
Seq-cst 和其它 ordering 混用时可能出现不符合预期的结果,如下面例子中,对 thread 1 来说,A sequenced before B,但对别的线程来说,它们可能先看到 B,很迟才看到 A,于是 C 可能看到 B,得到 r1 = 1,D 看到 E,得到 r2 = 3,F 看不到 A,得到 r3 = 0。
// Thread 1:
x.store(1, std::memory_order_seq_cst); // A
y.store(1, std::memory_order_release); // B
// Thread 2:
r1 = y.fetch_add(1, std::memory_order_seq_cst); // C
r2 = y.load(std::memory_order_relaxed); // D
// Thread 3:
y.store(3, std::memory_order_seq_cst); // E
r3 = x.load(std::memory_order_seq_cst); // F