RisingWave 窗口函数:滑动的艺术与对称的美学
目录:
本文发表于 RisingWave 中文开源社区。
窗口函数(Window Function)是数据库和流处理中一项非常常用的功能,该功能可用于对每一行输入数据计算其前后一定窗口范围内的数据的聚合结果,或是获取输入行的前/后指定偏移行中的数据。在其他一些流系统中,窗口函数功能也被称作“Over Aggregation”1。RisingWave 在此前的 1.1 版本中加入了窗口函数支持2。在 RisingWave 的窗口函数实现中,我们把实施窗口函数计算的算子称为 OverWindow 算子,本文将尝试解析 OverWindow 算子的设计与实现。
基本例子
首先用两个简单的例子展示窗口函数的基本用法。更完整的语法说明请参考 RisingWave 用户文档3。
例 1
下面的例子会持续计算每次股票价格更新事件时,当前价格相比上次更新时的价格差。
CREATE MATERIALIZED VIEW mv AS
SELECT
stock_id,
event_time,
price - LAG(price) OVER (PARTITION BY stock_id ORDER BY event_time) AS price_diff
FROM stock_prices;这里使用了 LAG 窗口函数,获得与当前行的 stock_id 相同的行中,按 event_time 排序,排在当前行的前一行的 price 值。与 LAG 相对应的,还有 LEAD 函数,用于获取后一行(按时间排序的话,即更新的一行——更“领先(lead)”的一行)。这类窗口函数我们称之为通用窗口函数(General-Purpose Window Function),与 PostgreSQL 中的概念保持一致4。
例 2
下面的例子则对每笔订单,计算该订单的用户在该订单前的 10 笔订单的平均消费金额。
CREATE MATERIALIZED VIEW mv AS
SELECT
user_id,
amount,
AVG(amount) OVER (
PARTITION BY user_id
ORDER BY order_time
ROWS BETWEEN 10 PRECEDING AND 1 PRECEDING
) AS recent_10_orders_avg_amount
FROM orders;这里使用了 AVG 函数,它实际上是一个聚合函数(Aggregate Function)。在 RisingWave 中,所有聚合函数都可以用作窗口函数,后面跟 OVER 子句指定计算窗口,我们称该类窗口函数为聚合窗口函数(Aggregate Window Function)。同样,这与 PostgreSQL 的概念保持一致4,便于用户快速理解。
两种输出触发模式
在此前的文章《深入理解 RisingWave 流处理引擎(三):触发机制》中5,我们已经介绍了 RisingWave 流计算引擎的两种输出触发模式,包括默认的 Emit-On-Update 和可通过关键字启用的 Emit-On-Window-Close 模式。OverWindow 算子也支持这两种输出模式。
通用模式(Emit-On-Update)
在通用模式下,OverWindow 算子在收到输入变更时,立即从内部状态中找到变更行所影响的行范围,并重新计算该范围内所有行对应的窗口函数结果。
上一节中两个 SQL 例子即是采用通用模式进行计算。
EOWC 模式(Emit-On-Window-Close)
通过在查询中加入 EMIT ON WINDOW CLOSE 关键字67,即可采用 EOWC 输出模式。
在 EOWC 模式下,OverWindow 仅在收到 watermark 时输出 ORDER BY 列和所对应的窗口均被 watermark “淹没”的行。这和我们熟悉的 EOWC 模式下 GROUP BY watermark 列的 HashAgg 算子行为有细微差别,在后者中,收到一个 group 的 watermark,即标志着该 watermark 前的 group 已经“完成”,即可输出;而在 OverWindow 中,需要等待两个条件满足才会输出,首先是 ORDER BY 列的“完成”,即输入行在 watermark 语义上允许下游可见,其次是窗口函数所定义的窗口的“完成”,即输入行所对应窗口的最后一个行也对下游可见。
出于性能考量,我们为通用模式和 EOWC 模式分别编写了两个执行器实现(不过许多代码是复用的),以充分利用两种输出模式的语义特征,下文将对它们进行分别介绍。
EOWC 版本:滑动的艺术
EOWC 版本的 OverWindow 算子(后称 EowcOverWindow)的实现算法相比通用版本要稍简单,因此这里先介绍它。
如前所述,EowcOverWindow 要等到一个输入行的 ORDER BY 列“完成”(条件 ①),且其所对应的窗口“完成”(条件 ②),才能输出这个行及其窗口函数计算结果。也就是说,即使窗口函数的 frame 是 ROWS BETWEEN 10 PRECEDING AND 1 PRECEDING,在 CURRENT ROW 的前一行的条件 ① 满足时,CURRENT ROW 的条件 ② 看起来就已经满足,算子仍然要等到 CURRENT ROW 的条件 ① 满足才能输出。我们可以换一个角度来理解,把输出中包含的所有输入列认为是 LAG(?, 0),进而就可以迅速发现条件 ① 实际上是条件 ② 的前提。
基于这个观察,我们把 EowcOverWindow 实现为两个阶段,对于一个输入行:
- 第一阶段等待条件 ① 满足,满足后把该行释放给第二阶段;
- 第二阶段等待条件 ② 满足,满足后计算窗口函数结果。
窗口函数的实际计算在两个条件都满足后才进行,可以避免大量不必要的无效计算。这与 HashAgg 算子的 EOWC 实现略有不同(后续会有文章介绍),因为 OverWindow 中一行修改会导致多行变更,而 HashAgg 中每个 group 至多有一行修改,前者无论在计算还是 I/O 层面均有明显的放大效应。
第一阶段:SortBuffer
第一阶段是对输入行的一个缓冲,又由于 watermark 的非递减性质,很容易把第一阶段的输出实现为是有序的,因此我们把第一阶段命名为 SortBuffer。更进一步,我们引入了一个名为 EowcSort 的算子来解耦 SortBuffer 与第二阶段,使 SortBuffer 可以在其他需要的地方复用。于是,EowcOverWindow 算子以 EowcSort 作为上游,其内部只需对满足条件 ① 的有序输入行实现第二阶段。
第二阶段:滑动窗口
由于条件 ② 满足之后才会进行计算,EowcOverWindow 需要先将输入行按 PARTITION BY 和 ORDER BY 列有序存储在其内部 state table 中。并且,对每个 partition,EowcOverWindow 在内存中维护着当前正在等待窗口完成的 CURRENT ROW(“当前行”)及其对应窗口(“当前窗口”)中的行(该内存结构可以在 recovery 时从 state table 重建)。
当一些输入行从 SortBuffer 进入 EowcOverWindow 时,后者便会找到对应 partition 的上述内存结构,如果其中的“当前窗口”已完成,则输出“当前行”和“当前窗口”上的窗口函数计算结果,并将“当前行”及其窗口滑动到下一行,如此循环直到“当前窗口”不再完成。窗口滑动时,一些最旧的行会被移出“当前窗口”,EowcOverWindow 于是可以把它们从 state table 中清除。
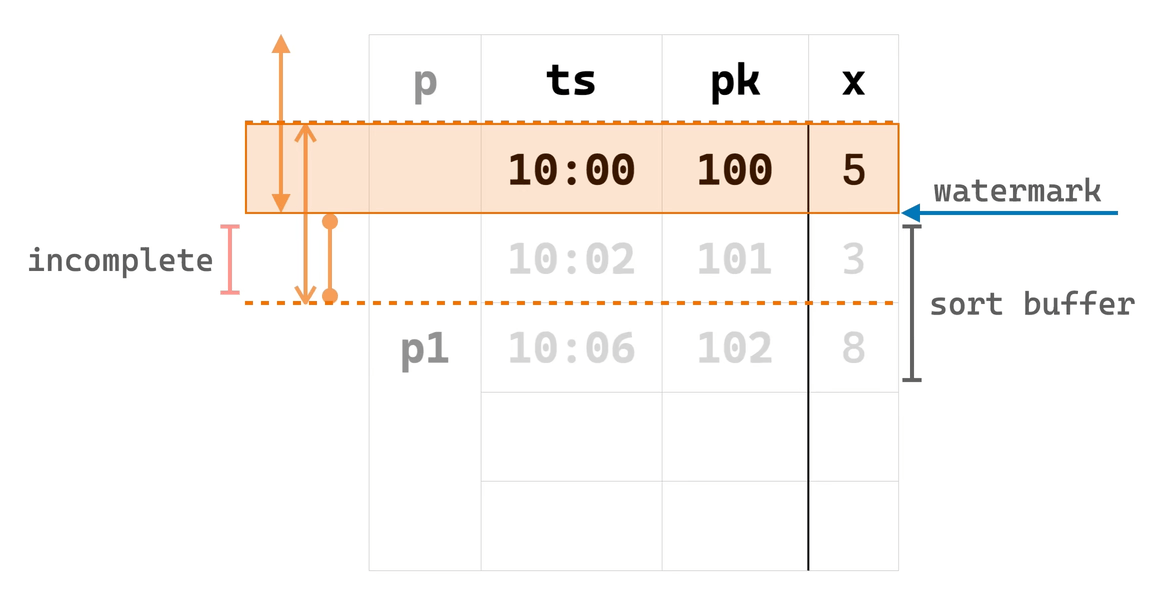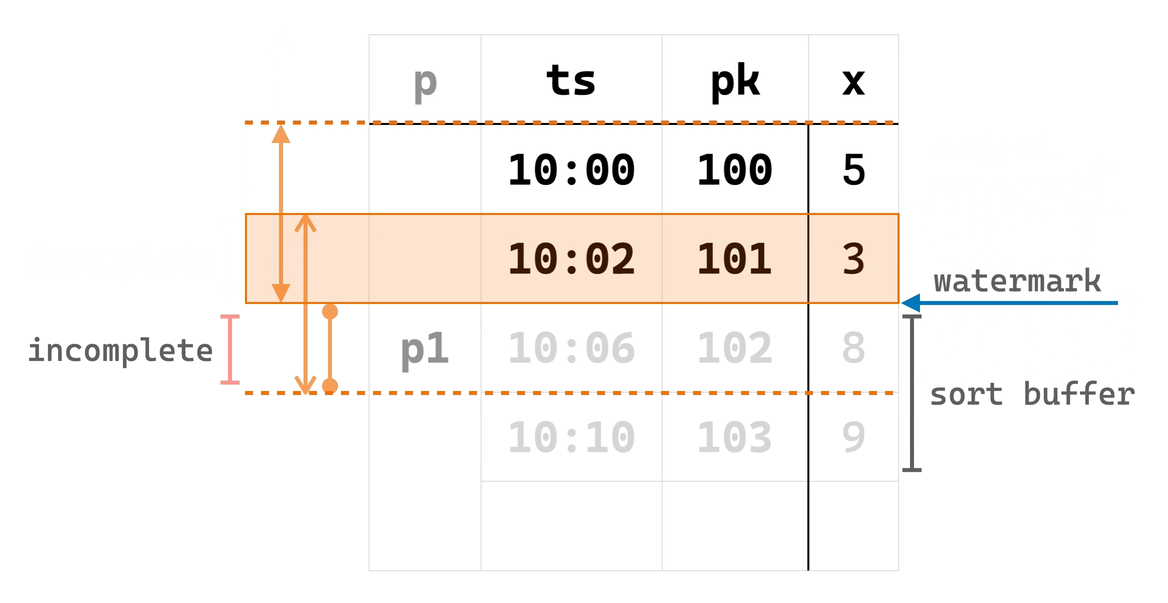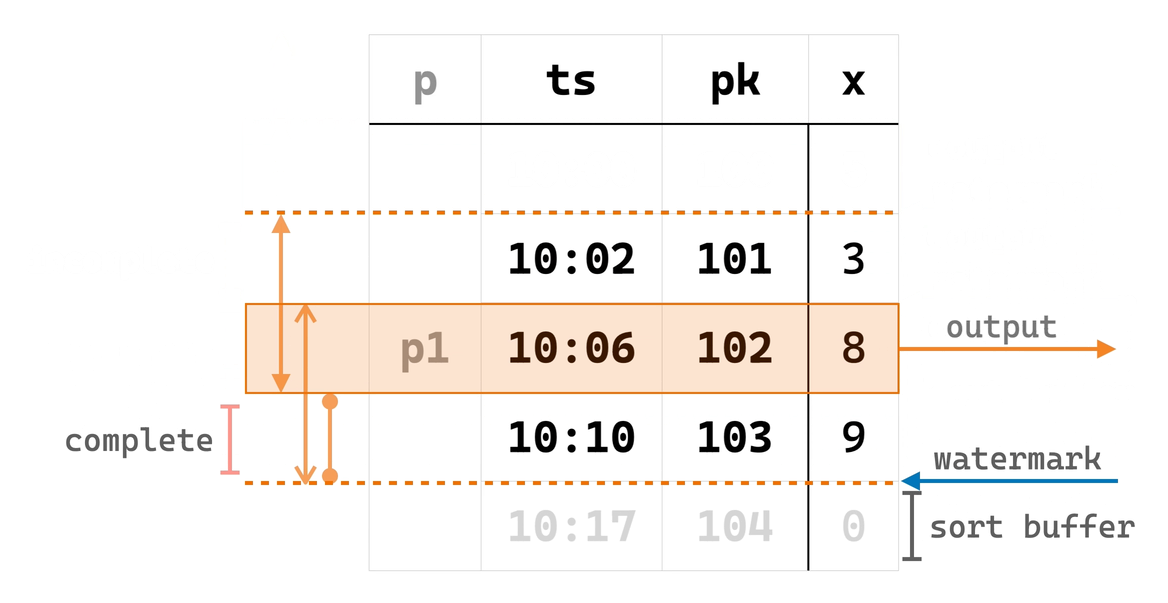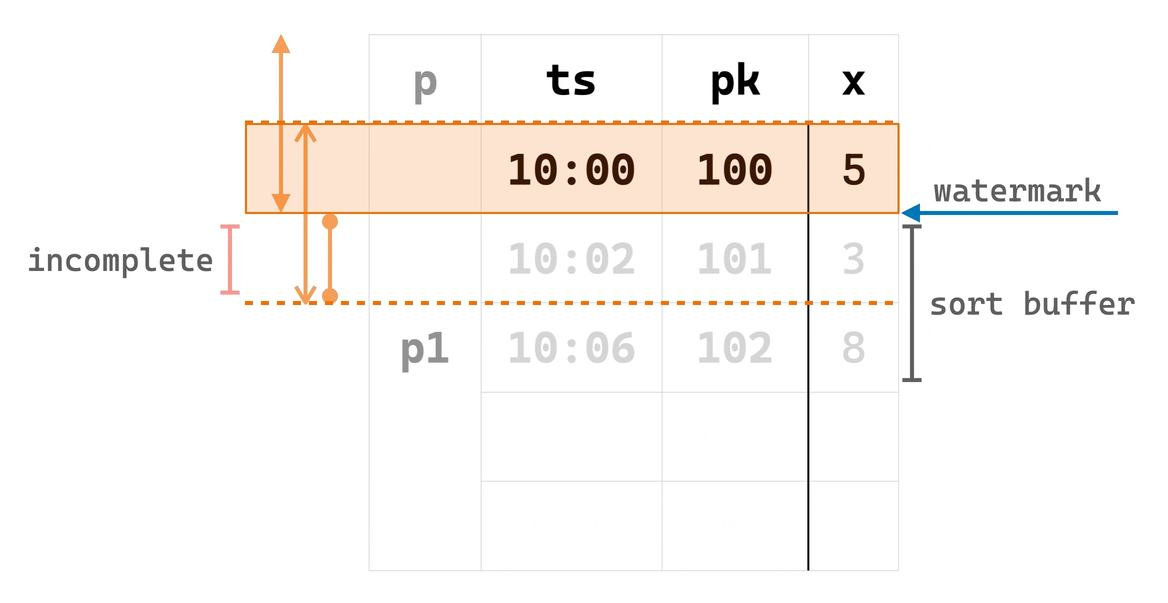
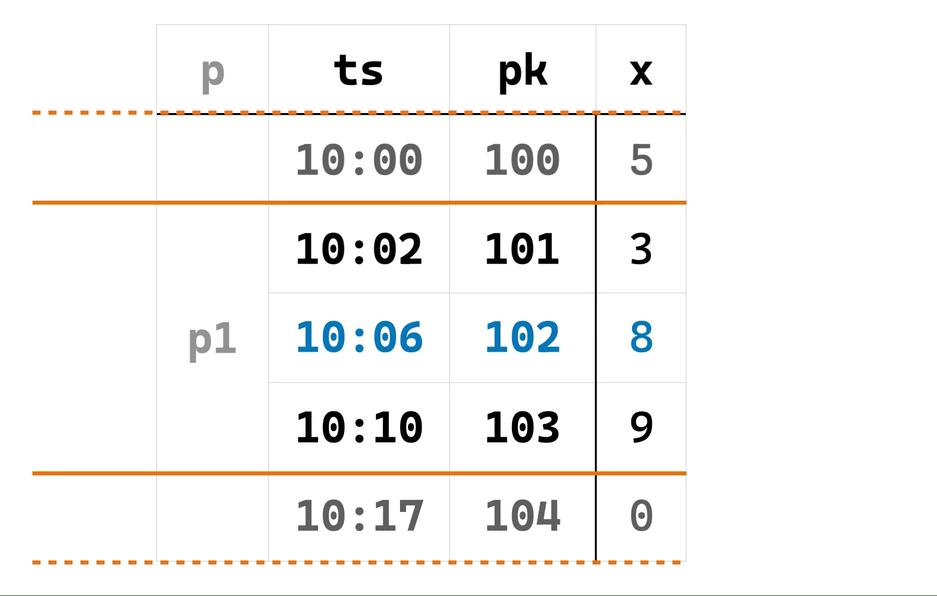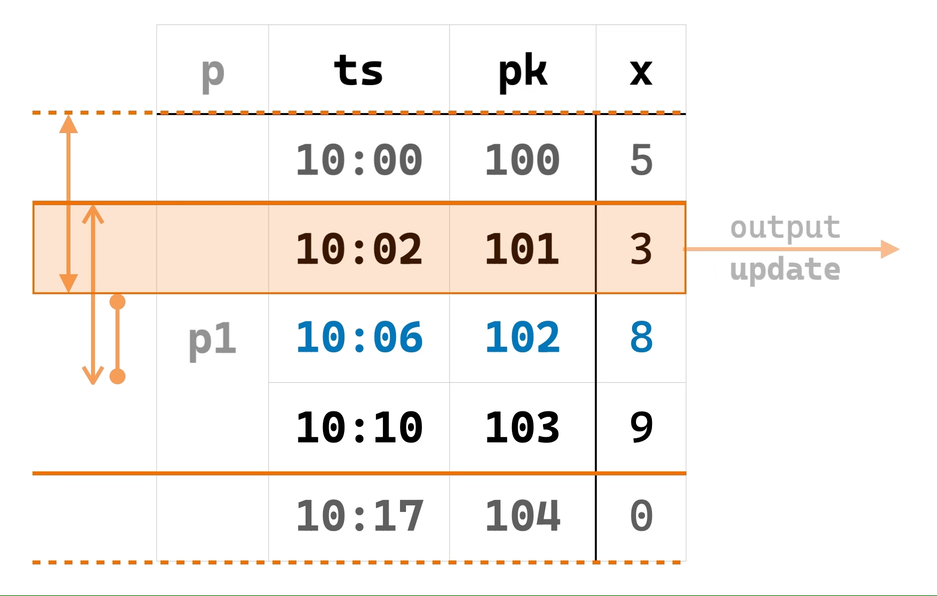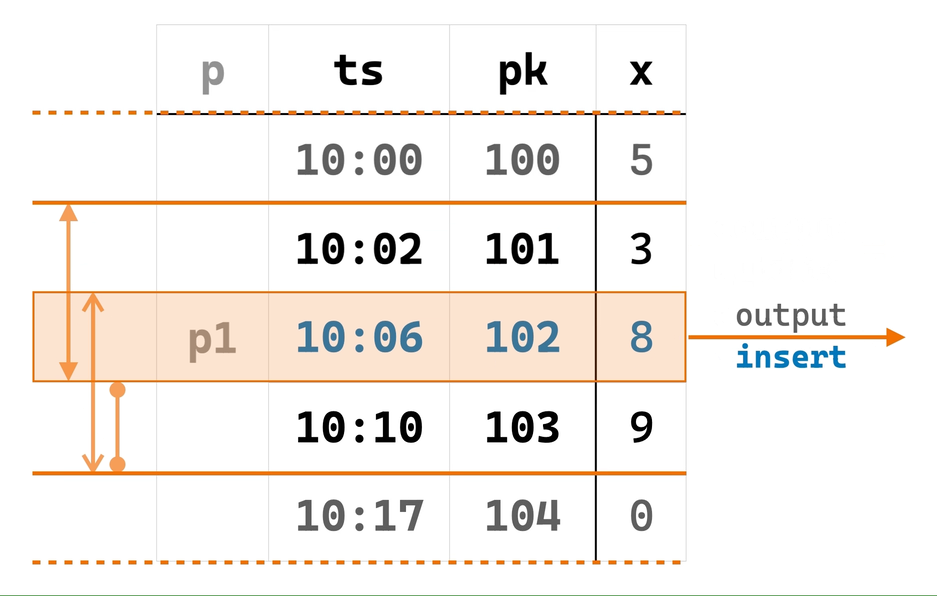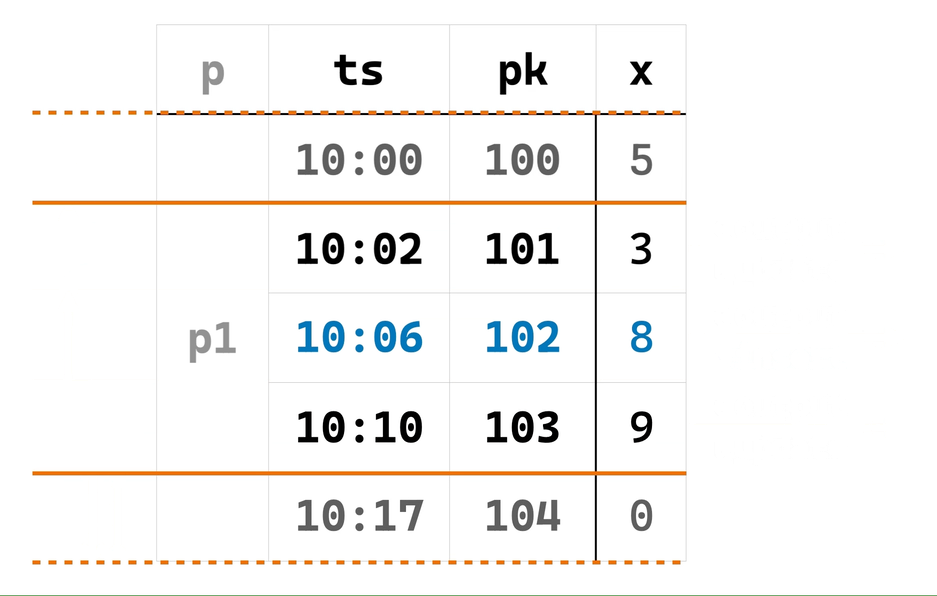
下面,我们通过一个例子来演示上述两个阶段的算法过程。考虑下面的查询7:
CREATE MATERIALIZED VIEW mv AS
SELECT
SUM(x) OVER (PARTITION BY p ORDER BY ts ROWS 1 PRECEDING),
SUM(x) OVER (PARTITION BY p ORDER BY ts ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING),
LEAD(x, 1) OVER (PARTITION BY p ORDER BY ts)
FROM t
EMIT ON WINDOW CLOSE;其中,三个窗口函数调用的 PARTITION BY 和 ORDER BY 相同(对于实际场景中不同的情况,优化器首先对查询进行拆分,由多个 OverWindow 算子处理),窗口 frame 不同。另外,ts 列定义了延迟为 5 分钟的 watermark。
在给出算法过程的动画演示之前,先给出动画中几种箭头所表示的含义:

现在,可以通过下面的动画理解 EowcOverWindow 的实现算法:
通用版本:对称的美学
相比 EOWC 版本,通用版本的 OverWindow(后称 GeneralOverWindow)看似更加简单粗暴,实际上实现起来是更为复杂的。
在 GeneralOverWindow 中,ORDER BY 列通常没有定义 watermark,于是输入行的 ORDER BY 列的值可能是任意大小的(表现在现实场景中就可能是几天前的数据仍然会被插入、修改或删除)。因此,不同于 EowcOverWindow 始终知道“当前窗口”在哪,GeneralOverWindow 在收到输入行之后,首先需要找到其对应的窗口,然后才能计算窗口函数结果。
例如,考虑上一节最后的查询例子(去掉 EMIT ON WINDOW CLOSE 关键字),假设我们已有如下数据:
ts pk x
10:00 100 5
10:02 101 3
10:10 103 9
10:17 104 0现在插入了 10:06 102 8 这样一行新数据(修改、删除的情形类似,后续只讨论插入),如下:
ts pk x
10:00 100 5
10:02 101 3
10:06 102 8 <-- insert
10:10 103 9
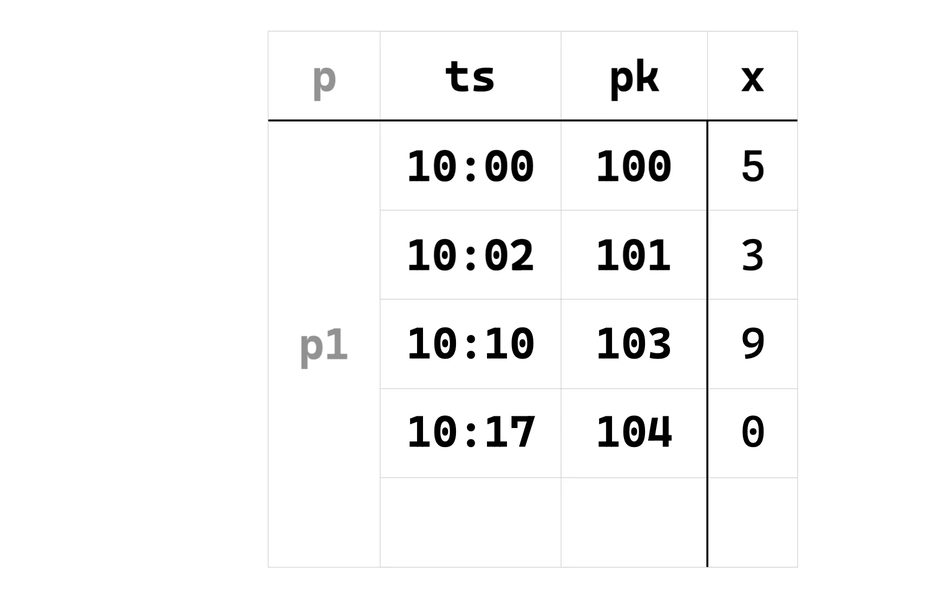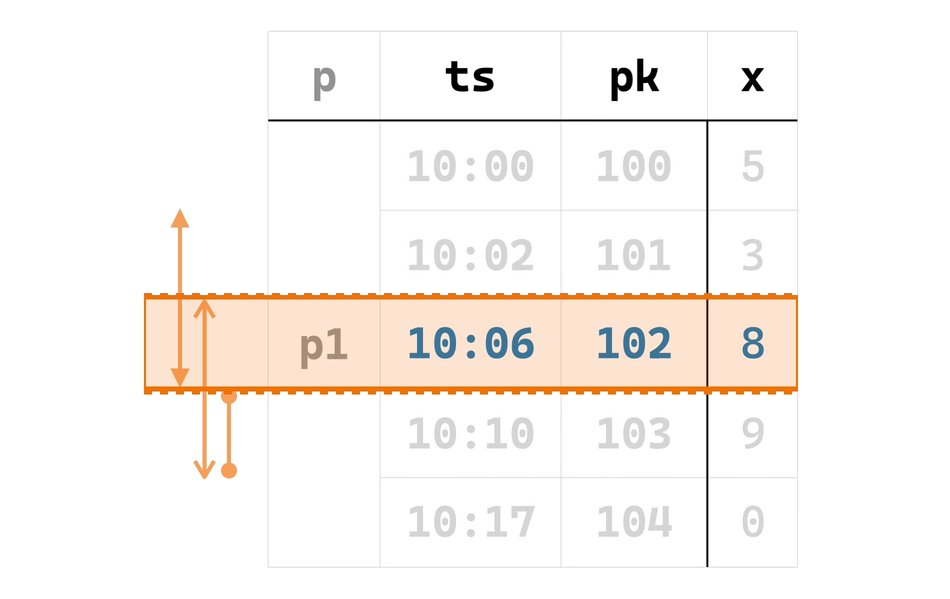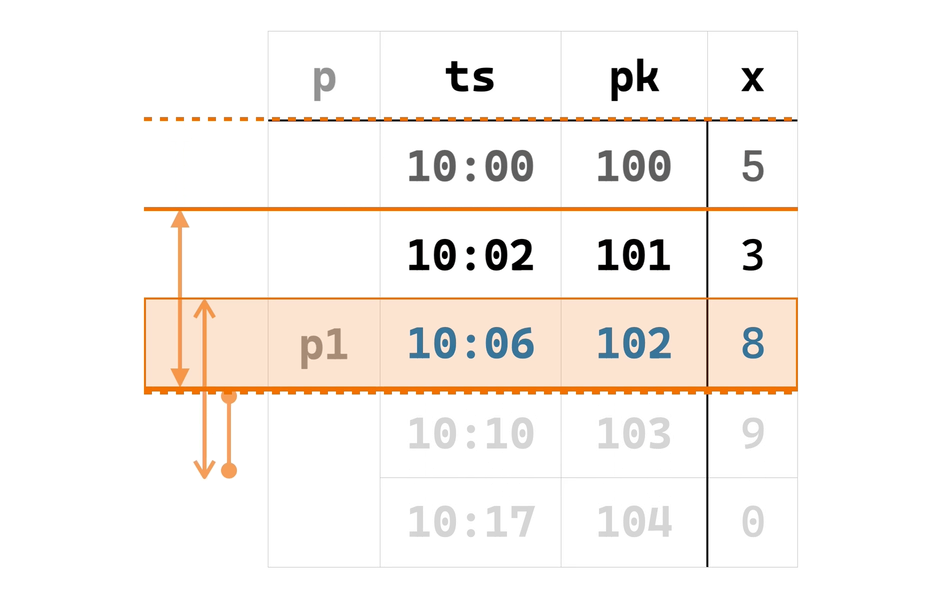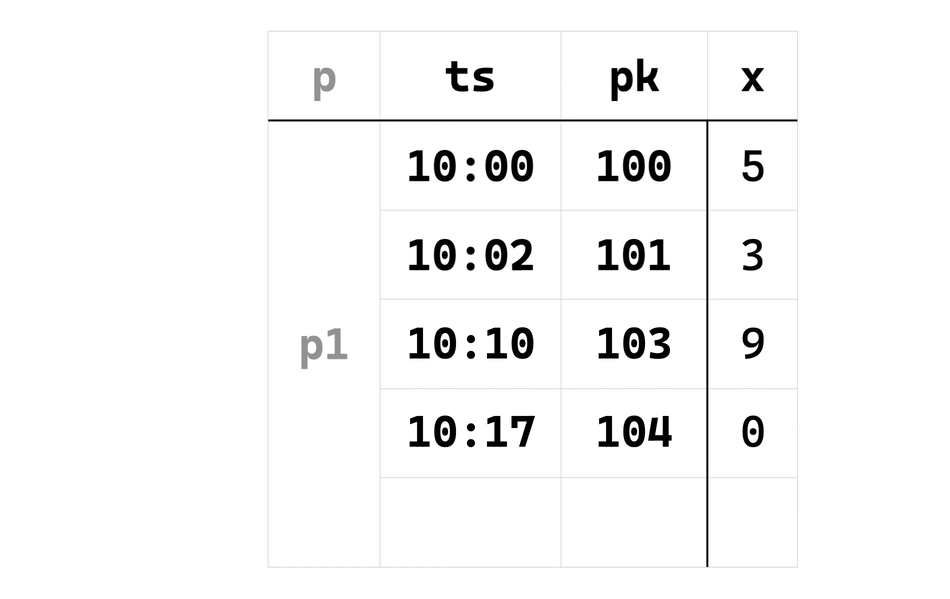
10:17 104 0按照所指定的窗口函数 frame,要计算 pk = 102 行的窗口函数结果,需要向前找一行、向后找一行,也就是说,CURRENT ROW 为 102 行的“当前窗口”范围是从 101 行到 103 行。
想到这里,我们立即可以发现,刚刚从新插入的行开始按窗口 frame 向前向后找到的“当前窗口”,仅能产生新插入的行对应的一行输出,然而,新插入的行很可能也属于此前已经输出过的其他窗口,从而导致曾经输出过的行需要修改。因此,我们需要改变算法思路,不能把当前插入/修改/删除的行作为 CURRENT ROW 来找窗口,而要把它当作某个窗口 A 的最后一行和另一个窗口 B 的第一行,找到窗口 A 和 B,才能正确为所有受影响的行产生新输出。
同样以刚刚的数据为例,把 102 行当作窗口 A 的最后一行,倒着找,可以找到 A 的 CURRENT ROW 是 101 行,进而找到窗口 A 的第一行是 100 行。这里我们将窗口 A 的第一行 100 行标记为 first_frame_start、CURRENT ROW 即 101 行标记为 first_curr_row。对称地(点题了!),把 102 行当作窗口 B 的第一行,顺着找,可以找到 B 的 CURRENT ROW 是 103 行,进而找到窗口 B 的最后一行是 104 行,和前面类似,分别把它们标记为 last_curr_row 和 last_frame_end。这个过程如下面动画所示:
找到 (first_frame_start, first_curr_row, last_curr_row, last_frame_end)(分别对应动画最后的四个横线)这整个受新输入行影响的范围后,只需要复用 EowcOverWindow 第二阶段的代码,即可滑动地计算从 first_curr_row 到 last_curr_row 的新输出结果,如下面动画所示:
-
Flink Over Aggregation 文档,https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/sql/queries/over-agg/ ↩
-
RisingWave 1.1 版本亮点一览,https://mp.weixin.qq.com/s/c0VHTebJ3zwiqma2z352VA ↩
-
RisingWave 窗口函数文档,https://docs.risingwave.com/docs/current/window-functions/ ↩
-
PostgreSQL 窗口函数文档,https://www.postgresql.org/docs/current/functions-window.html ↩↩
-
深入理解 RisingWave 流处理引擎(三):触发机制,https://mp.weixin.qq.com/s/eQjGEGei9vfrXhAjcRe67w ↩
-
RisingWave Emit-On-Window-Close 文档,https://docs.risingwave.com/docs/current/emit-on-window-close/ ↩
-
由于 EOWC 模式还属于实验性功能,其行为和语法都可能有所变化,例如语法在 1.2 版本发生了一次变化,调整了
EMIT ON WINDOW CLOSE关键字的位置,在使用时请注意参考所使用版本对应的文档。 ↩↩